
Motivation
This writing began as a reflection from CS312: Natural Language Processing. During the transformer architecture part, the flow and thought process of the model still felt like a black box to me. I could repeat the words attention, embedding, and logits, but I did not yet feel the computation from the inside. That gap bothered me enough that I started rebuilding the architecture piece by piece.
What helped most were two complementary explanations: Stanford’s CME295 material on transformers and large language models, and Neel Nanda’s walkthrough-style explanations of transformer internals (Stanford CME295; Nanda, 2021). The goal of this note is not to give the most formal account possible, but to reconstruct the model in the order that made it click for me.
What is a Transformer?
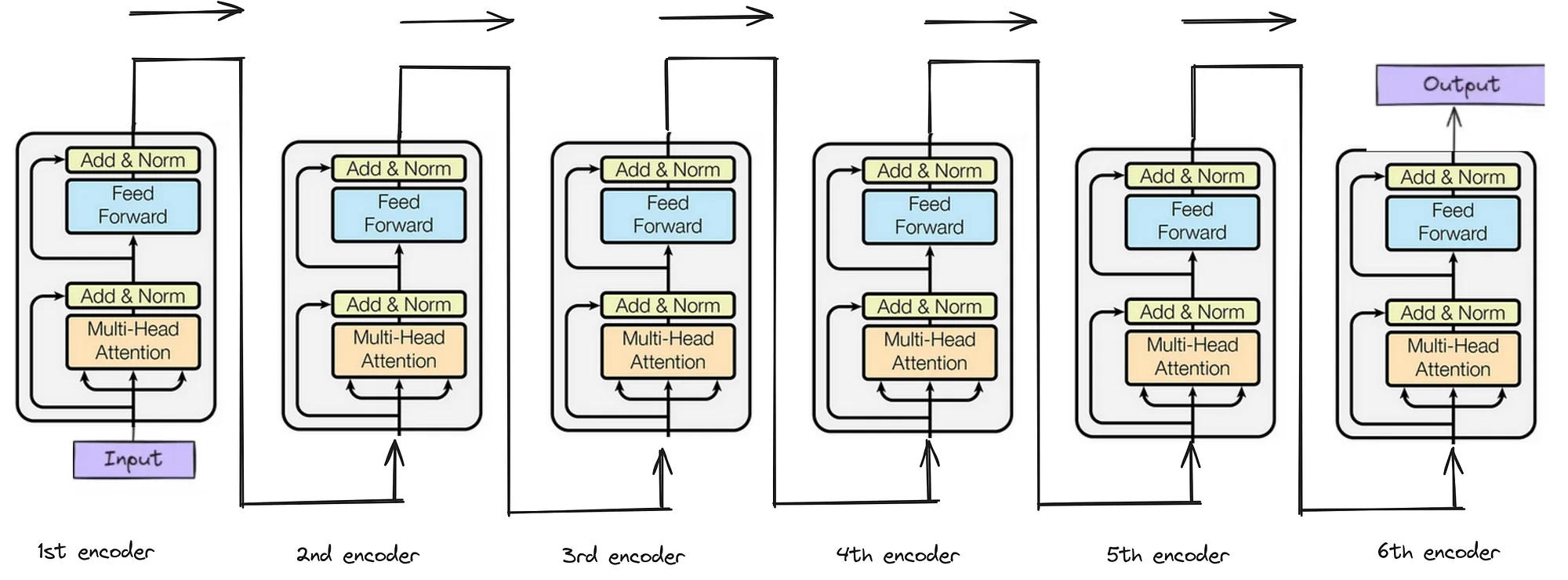
At a high level, a transformer is a sequence model that repeatedly updates a shared representation of every token position. It begins by embedding tokens into vectors, adds positional information, and then runs the sequence through a stack of transformer blocks. Each block contains an attention sublayer and an MLP sublayer, both of which write back into the same residual stream. At the very end, the model maps those final vectors into logits over the vocabulary (Stanford CME295; OpenAI, 2019).
The simplest way I now think about a transformer is this: it is a machine for moving information between positions, transforming that information locally, and preserving intermediate computation in one shared representational space.
Inputs and Outputs
The input to a language model is a sequence of token IDs. Each token ID indexes into an embedding matrix, producing a dense vector in model space. Positional embeddings are then added so the model has some notion of order. Those vectors enter the residual stream, pass through a stack of transformer blocks, and finally get projected back into vocabulary space as logits (OpenAI, 2019).
So the core shape is:
- token IDs
- token embeddings
- positional embeddings
- residual stream through transformer blocks
- final LayerNorm
- unembedding into logits over vocabulary
That sequence is simple enough to write in one line, but each step hides a lot of conceptual structure.
Tokens
Before the model can do anything interesting, text has to be turned into discrete pieces. Those pieces are tokens, not necessarily words. Sometimes a token is a whole word, sometimes part of a word, and sometimes punctuation or whitespace. What matters is that the sequence has been discretized into IDs that the model can look up.
A transformer never directly sees “meaning” in the ordinary human sense. It sees a sequence of indices, then turns them into vectors. So whenever I think about transformers now, I try to remember that meaning enters the system only through learned geometric structure in embedding space and later transformations.
Logits and Generation
At the output side, the model produces logits: one scalar for every vocabulary item. These logits are not probabilities yet. They are unnormalized scores. A softmax turns them into a distribution over next-token candidates, and generation proceeds by selecting or sampling from that distribution.
Each call adds one token, but because the full context is reprocessed at each step, the model conditions on everything that came before (OpenAI, 2019). That is why generation feels sequential even though the architecture itself is built from repeated vector transformations.
Architecture
GPT-2 small is a useful concrete reference point for understanding the shape of a transformer (OpenAI, 2019). The dimensions I keep coming back to are:
| Parameter | Value | Meaning |
|---|---|---|
d_model | 768 | Residual stream dimension |
n_layers | 12 | Number of transformer blocks |
n_heads | 12 | Attention heads per block |
d_head | 64 | Dimension per head |
d_mlp | 3072 | MLP hidden dimension |
n_ctx | 1024 | Maximum context length |
d_vocab | 50257 | Vocabulary size |
The high-level flow is token embeddings plus positional embeddings feeding into a residual stream, which then passes through 12 transformer blocks. Each block contains a LayerNorm, an attention sublayer, another LayerNorm, and an MLP sublayer. A final LayerNorm and unembedding step produce the output logits. One important clarification is that when people say a transformer has k layers, they often mean k blocks, even though each block contains both an attention sublayer and an MLP sublayer. So GPT-2 small has 12 blocks but 24 major sublayers inside them (Stanford CME295).
Attention
Attention is the only part of the transformer that explicitly moves information between positions in the sequence. Everything else, including embeddings, MLPs, and LayerNorm, operates position-wise. That is what makes attention so central: it decides where a position should read from.
Each attention layer contains n_heads heads that act independently and additively. Their outputs are summed and written back to the residual stream. The most useful conceptual split for me was this:
- Pattern: which earlier positions should this token attend to?
- Move: what information should be copied back from those positions?
That separation helped me finally understand why queries and keys are not the same thing as values. Queries and keys determine the attention pattern. Values, together with the output matrix, determine what actually gets moved, which is very close to the framing Neel Nanda emphasizes in his transformer-circuits explanations (Nanda, 2021).
Parameter shapes per attention layer
For GPT-2 small, the parameter shapes are:
W_Q, W_K, W_V:[n_heads, d_model, d_head] = [12, 768, 64]W_O:[n_heads, d_head, d_model] = [12, 64, 768]b_Q, b_K, b_V:[n_heads, d_head] = [12, 64]b_O:[d_model] = [768]
That table is useful because it makes attention feel less like a slogan and more like a concrete bundle of matrices.
MLP Layers
After each attention sublayer, a two-layer MLP processes every position independently. The standard shape here is a projection up to d_mlp = 4 × d_model, followed by a nonlinearity such as GELU, followed by a projection back down to d_model. In GPT-2 small that means going from 768 up to 3072 and then back down again (OpenAI, 2019).
Once attention has routed relevant information to the right place, the MLP is where more of the local computation happens. It performs feature detection, nonlinear transformation, and recombination. The exact expansion ratio is less important than the fact that this sublayer gives the model expressive power beyond linear copying.
Residual Stream
The residual stream is the central object of the transformer. At every position in the sequence there is a vector of dimension d_model that begins as the embedded input and then gets updated additively by each attention and MLP sublayer. Nothing fully replaces it. Each sublayer reads from the current residual stream and writes its output back into that same shared space.
That additive structure is what makes transformers compositional. One head can build on the output of another because they are all using a shared memory space. For me, this was one of the most important mental shifts: the transformer is not just a stack of isolated modules. It is a sequence of edits to one evolving representational object, which is also why transformer-circuits style analysis finds the residual stream so useful as a conceptual anchor (Nanda, 2021).
LayerNorm
LayerNorm appears at the start of each sublayer and again before the final unembedding. It normalizes each residual stream vector by subtracting the mean and dividing by the standard deviation, then applies learned scale and bias parameters. Its role is partly stabilization, partly keeping the scale of representations in a workable range as information accumulates across many additive updates (Stanford CME295).
I do not usually think of LayerNorm as where the intelligence is, but it is one of the things that keeps the rest of the system trainable and coherent.
Positional Embeddings
Attention by itself is position-agnostic. Without positional information, the model has no built-in sense of order or distance. GPT-2 solves this by learning absolute positional embeddings of shape [n_ctx, d_model], which are added to token embeddings before the first transformer block (OpenAI, 2019). That means the model learns which positional information is useful rather than having it hard-coded.
This is one of those places where the design feels almost deceptively simple: just add another vector. But that addition gives the model access to sequence order all the way downstream.
Putting it Together
The full forward pass of a GPT-2 style transformer looks like this:
- Embed token IDs into vectors.
- Add positional embeddings.
- Pass the residual stream through each transformer block.
- Apply the final LayerNorm.
- Unembed into logits over the vocabulary.
What makes this architecture powerful is not any single component in isolation. It is the way these pieces fit together: attention routes information, MLPs transform it, residual connections preserve and accumulate it, and LayerNorm keeps the whole process stable enough to learn.
Once I rebuilt the architecture from scratch and checked each piece against GPT-2, the transformer stopped feeling like a sealed black box. That was the feeling I had been chasing.