
Introduction
One of the quietest but most important changes in NLP was the shift from symbolic word representations to learned vector representations. Before that shift, words were often treated as isolated units. They could be indexed, counted, and compared, but the representation itself did not carry any real notion of similarity. The model knew that two words were different, but not why they might belong near each other.
That is what made embeddings feel so consequential to me. They changed the basic object of language processing. A word stopped being just a discrete label and became a point in a learned geometric space. Once that happened, similarity, analogy, clustering, and transfer all became easier to express inside the model.
Why this topic matters
What interests me here is not only the history of word embeddings, but the conceptual shift they introduced. The field moved from hand-designed symbolic representations toward learned representational spaces. That changed how models store structure and how they generalize.
In that sense, embeddings did more than improve performance. They changed what a language representation could be.
Distributional hypothesis
The intuition behind word embeddings is often summarized by a familiar slogan: you shall know a word by the company it keeps. Meaning is not assigned in isolation. It emerges from contextual regularities.
A model does not need a dictionary definition of bank to begin learning something about it. It can instead infer structure from repeated co-occurrence patterns. If river and shore appear around one use of bank, while loan and interest appear around another, those neighborhoods begin to shape representation.
So the jump from symbolic NLP to neural representation learning is also a jump from static encoding to contextual statistics.
From counts to neural models
The cleanest place to begin is with one-hot encoding. If a vocabulary has size V, then each word is represented by a vector of length V with exactly one nonzero entry. The representation is sparse, high-dimensional, and completely orthogonal to every other word.
That representation is useful for indexing, but not for meaning. Two words that feel similar to a human, like cat and dog, are just as orthogonal as two unrelated words. One-hot vectors tell the model identity, but not structure.
Neural language models change this completely. Instead of treating representation as a fixed preprocessing choice, they learn dense vectors through prediction. Representation becomes useful because it supports the task itself. That is the bridge from symbolic bookkeeping to learned geometry.
CBOW and Skip-gram
Word2Vec is one of the clearest examples of this shift. Its contribution was not just computational efficiency, but a particularly influential way of learning distributed word representations from local context windows.
The central idea is simple: train a shallow neural model on a predictive task, then keep the learned embedding weights. Those weights become the word vectors.
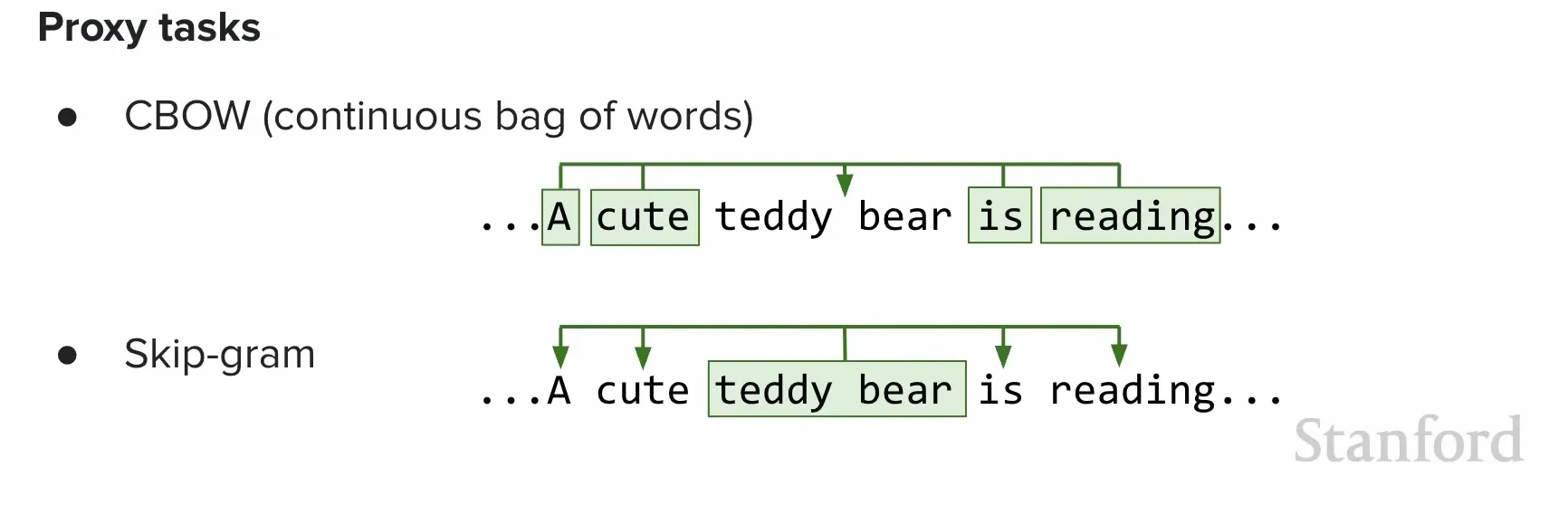
Continuous Bag of Words, or CBOW, predicts the center word from surrounding context words. The context words are treated as an unordered window, their embeddings are combined, and the model tries to predict which word belongs in the middle.
Skip-gram reverses the direction. Instead of predicting the center word from context, it predicts surrounding context words from the center word. That reversal changes the pressure on the representation: now the center word must support multiple nearby predictions.
I think of CBOW and Skip-gram as two different lenses on the same question. Should context explain the target, or should the target explain its context?
What the model learns
The move to embeddings allows words with similar usage patterns to end up near one another in space. Meaning becomes something the model approximates through distributional structure. Words that appear in similar contexts tend to acquire similar representations.
That is the point where representation starts to feel less like bookkeeping and more like learning.
This is also why analogy demonstrations became so famous. They were not the deepest proof of understanding, but they made the geometry visible. Vector arithmetic seemed to reveal that the model had captured some relational regularities rather than only memorizing isolated facts.
Why neural language models matter
Part of the reason embeddings were such a breakthrough is that they gave NLP a smoother representational space. Once words lived in vectors rather than orthogonal slots, it became possible to generalize across neighborhoods. A model could transfer what it learned about one region of semantic space to nearby regions.
That is why neural language models matter so much historically. They sit at a hinge point in NLP. They are simple enough to inspect, but important enough to explain a major shift in how the field thinks about language.
Transformers did not appear out of nowhere. Contextual representations did not appear out of nowhere. They were built on the earlier insight that useful linguistic structure could be learned rather than manually specified.
What I find interesting
At the same time, static embeddings also have real limits. A single vector for a word cannot fully capture polysemy or context-sensitive meaning. The word bank still gets one representation even though its meaning may change depending on the sentence.
That limitation is exactly what makes this stage of NLP so interesting to me. Word2Vec is not the final answer, but it is one of the clearest bridges to later contextual and transformer-based models. It is where the representational logic becomes visible.
Closing thought
The reason I keep returning to neural language models is that they make a major intellectual shift in NLP feel inspectable. Once words become vectors learned through prediction, many later developments begin to make more sense.
That is why I still think CBOW, Skip-gram, and Word2Vec matter. They are not only historical artifacts. They are one of the clearest entry points into how NLP learned to represent meaning.