
Why evaluation matters
What drew me into model evaluation is that it sits in an uncomfortable but important place between research and judgment. We all want to say that a model is good, reliable, or aligned, but the moment we ask “good according to what?” the real work begins.
Evaluation is not just a reporting ritual at the end of training. It shapes what researchers optimize for, what product teams trust, and what kinds of claims become legible to the public. A benchmark can look objective, but each one quietly encodes assumptions about the task, the acceptable format of an answer, and what sort of generalization is being rewarded.
That is why I keep returning to evals. They are not merely measurement tools. They are part of the interface between models and institutions.
Benchmarks and task design
Benchmarks matter because they turn vague impressions into something more inspectable. They let us compare systems across versions, architectures, and prompting strategies. But I do not think a benchmark should ever be mistaken for the capability itself.
A benchmark is a proxy. Sometimes it is a good proxy. Sometimes it is brittle, narrow, or easy to game. Sometimes it captures task performance while missing the thing we actually care about, such as robustness under distribution shift or usefulness in real workflows.
This becomes even more obvious in language tasks. A model may do well on a static benchmark because it has learned patterns that match the test format, not because it has developed a deeper or more stable competence. That is one reason why benchmark design is not secondary. The structure of the task changes what success means.
Search, retrieval, and benchmark framing
In retrieval-style tasks, evaluation becomes even trickier because the model is not operating in a vacuum. It may depend on document selection, chunking, ranking, prompt framing, and answer synthesis. A poor score may reflect weak retrieval rather than weak reasoning, while a good score may conceal lucky document matches.
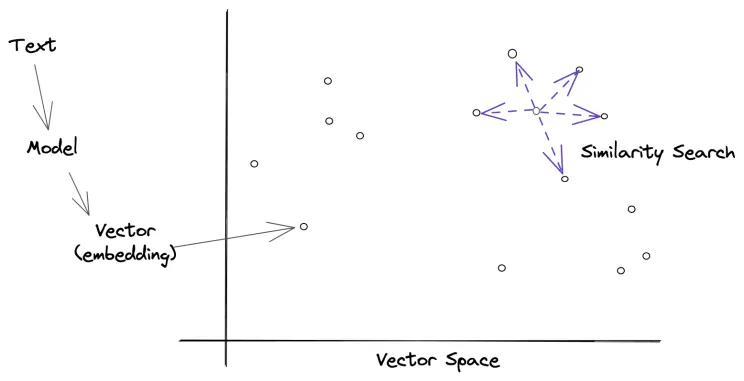
That is why benchmark framing matters so much. The system being evaluated is often larger than the base model itself.
Overlap metrics and approximation
One recurring theme in NLP evaluation is that many metrics are forms of approximation. They stand in for the richer question of whether an answer is actually good. Some reward overlap. Some reward fluency. Some reward semantic similarity. None of them fully collapse into human judgment.
That is not a flaw unique to NLP. It is a normal consequence of trying to measure something messy with a finite procedure. Still, it means we should read metrics as partial signals rather than final verdicts.
Perplexity
Perplexity is one of the classic intrinsic metrics for language models. Intuitively, it measures how surprised a model is by a sequence of text. A lower perplexity means the model assigns higher probability to the observed tokens.
That makes perplexity useful for tracking next-token prediction quality, but it also makes its limitations clear. A model can have strong perplexity while still producing poor downstream outputs. Conversely, a model might support useful behavior that is not fully captured by token-level surprise.
Perplexity is most meaningful when we remember what it actually measures: the quality of a model’s predictive distribution over text, not its full practical usefulness.

BLEU and ROUGE
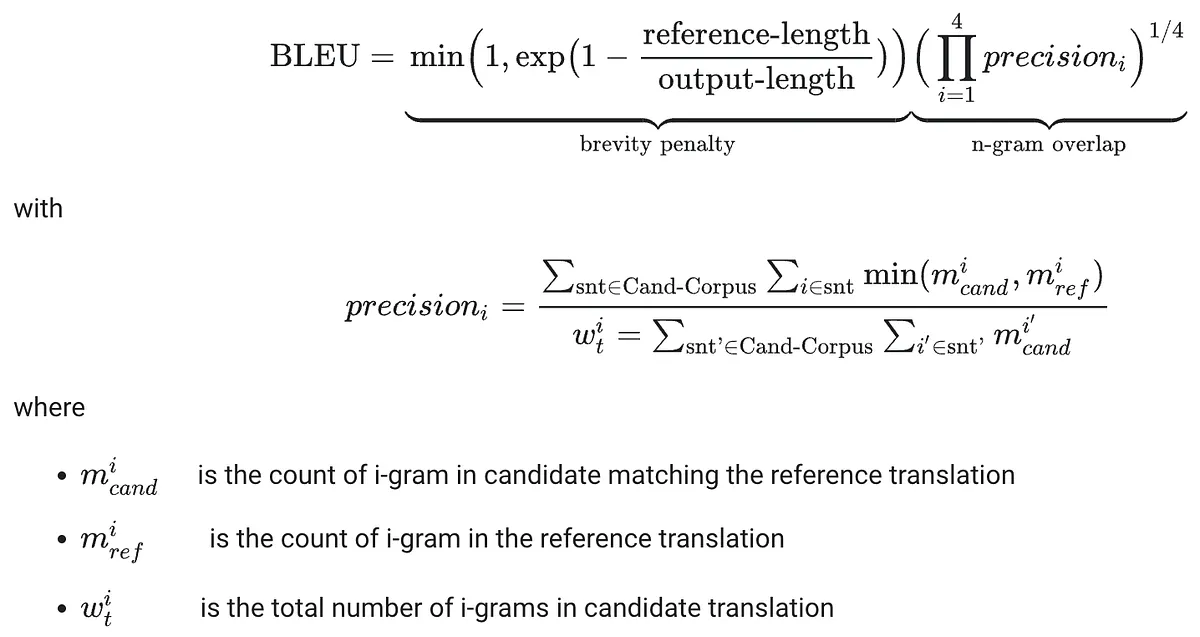
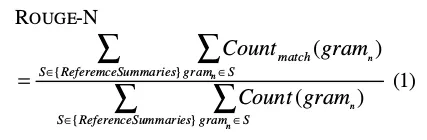
BLEU and ROUGE come from a slightly different tradition. They compare generated text against one or more references and reward n-gram overlap. BLEU is more common in translation-style settings, while ROUGE is especially common in summarization.
These metrics are valuable because they are cheap, standardized, and easy to reproduce. But they also reveal the limits of overlap-based evaluation. A model can express the same idea in a different surface form and still be penalized. It can also exploit formulaic phrasing and score well without being especially insightful.
So I think of BLEU and ROUGE as rough instruments. They are helpful for comparison, but not sufficient for interpretation.
BERTScore and semantic similarity
Metrics such as BERTScore try to move beyond raw token overlap by comparing contextual embeddings. That is appealing because meaning often survives paraphrase. Two answers can differ lexically while remaining semantically close.
This is a real improvement, but it still does not solve everything. Semantic similarity is not identical to correctness. A response can sound conceptually nearby while still missing the specific demand of the task. Embedding-based metrics are therefore better thought of as richer approximations, not as replacements for judgment.
Still, I like BERTScore because it pushes evaluation closer to the question people actually care about: not “did the system copy the same words?” but “did it preserve the same content?”
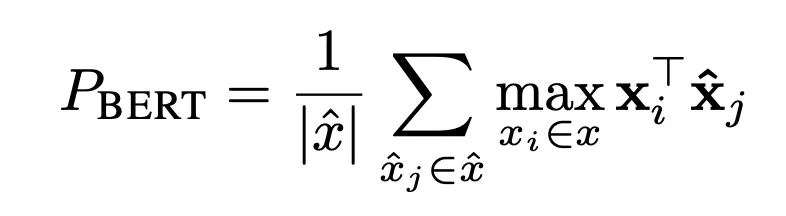
Human evaluation and its problems
Whenever automatic metrics feel too thin, the obvious answer is human evaluation. And often that is right. Humans can judge coherence, usefulness, tone, subtle error, and pragmatic fit in ways automatic metrics still struggle to match.
But human evaluation is not a magic escape hatch. It is costly, slow, and sensitive to prompt wording, rubric design, annotator disagreement, and task ambiguity. Different raters bring different expectations about what counts as a good answer. Even the same rater may shift over time.
So the interesting question is not whether we should choose automatic evaluation or human evaluation. Usually we need both. The real problem is how to combine them without pretending either one is perfect.
Confidence, logprobs, and calibration
One of the most useful shifts in my own thinking came from looking not only at answers, but at the model’s confidence structure. Token probabilities and logprobs can help reveal whether the model is uncertain, overconfident, or sharply committed to the wrong completion.
That does not mean confidence is truth. Models can be confidently wrong. But confidence is still informative. It lets us reason about calibration, ranking, fallback behavior, and when a system might need abstention or review.
This matters especially in applications where reliability is not just about average score, but about whether the system knows when it may be failing.
What I keep coming back to
The main lesson I keep returning to is that evaluation is not a single number problem. It is an interface problem between task design, metric choice, human judgment, and deployment context.
A good eval is not the one that looks most scientific on a dashboard. It is the one that makes the underlying claim more honest. That usually means mixing multiple signals, being explicit about the limits of each metric, and resisting the temptation to let a benchmark stand in for the whole phenomenon.
I do not think evaluation will ever become fully clean or fully settled. But that is exactly why it remains interesting.